Augmenting decision trees with LLMs
12 Sep 2023Machine learning models perform well when there is an abundance of data. They handle high dimensionality well, perform calculations rapidly, and do not rely on lazy approximations for their guesses. The inference abilities of humans and language models, however, do not scale well with data. We are, however, expert transfer learners, with strong priors about the behaviors of different classes of things.
Suppose you’re hiking in a foreign land cataloging the animals you’ve seen: a couple of birds, a salamander, and a baby deer. For each animal you enter a description into your database and mark whether it was dangerous or safe. Suddenly you come across an animal you have never seen before. Four-legged and the size of a large dog, salivating, it bares its fangs and lets out a gurgling hiss in your direction. Having seen your fair share of nature documentaries, you may classify this as a dangerous situation, despite having no training data specific to this particular animal. Double-checking yourself, you build a decision tree from your database to classify animals as dangerous or safe. But you’ve only seen a few animals, and your decision tree algorithm finds that it gains more information splitting on the “dog-like” attribute than the “size of fangs” one. All the dog-like animals you have seen are safe, so the decision tree marks this encounter also “safe.” Until you’ve collected a large amount of data, you’re probably better off trusting your intuition, or giving the animal description to GPT-4 and zero-shotting it.
 TabLLM: LLMs do well with little tabular data.
TabLLM: LLMs do well with little tabular data.
Let’s compare the pros/cons of decision trees and language models:
Decision Trees
Pros: Easy to interpret, scale well with data, cheap
Cons: No transfer learning, perform poorly with sparse data
Language Models
Pros: Perform well with sparse or zero data
Cons: Blackbox, expensive by comparison
Of course, language models are not necessarily blackboxes. If you have access, you can try to do interpretation of the network itself, or you can ask the language model to explain its reasoning before arriving at its conclusion using, for example, chain of thought. But the former is difficult and the latter fallible: language models struggle with reasoning steps, may be inconsistent with reasoning steps, and asking for reasoning steps is costly.
If we can learn to build a decision tree from sparse data, we can combine the pros and mitigate the downsides of each of these approaches. Robust decision trees from sparse data are
- easy to interpret,
- consistent and inexpensive for repeated inference,
- few-shot learners, and
- scalable.
In other words, we want to combine the benefits of simple symbolic models with the few-shot learning abilities of language models.
The decision tree construction algorithm recursively chooses the next split in the dataset until some stopping rule is satisfied. When building a decision tree for classification on continuous data, the split selection process consists of two parts:
- Choosing the feature to split on
- Choosing the value of that feature to split on
The feature/value node that maximizes information gain in the training set is chosen.
When we have sparse data, sometimes pretty unhelpful splits are chosen and the tree focuses on features that do not actually provide much information toward the classification task. Instead of searching the entire space of feature/value pairs, we can use the language model to choose the next best feature for us, pulling from its latent knowledge about what attributes are most relevant to the domain. So, we replace Step 1 with a prompt to the language model. Formally, we can imagine a feature selector F that takes a dataset D that has two methods, iterate through all possibilities in the training set or ask the language model for the feature, and sends that feature to the value selector V which returns the feature/value pair.
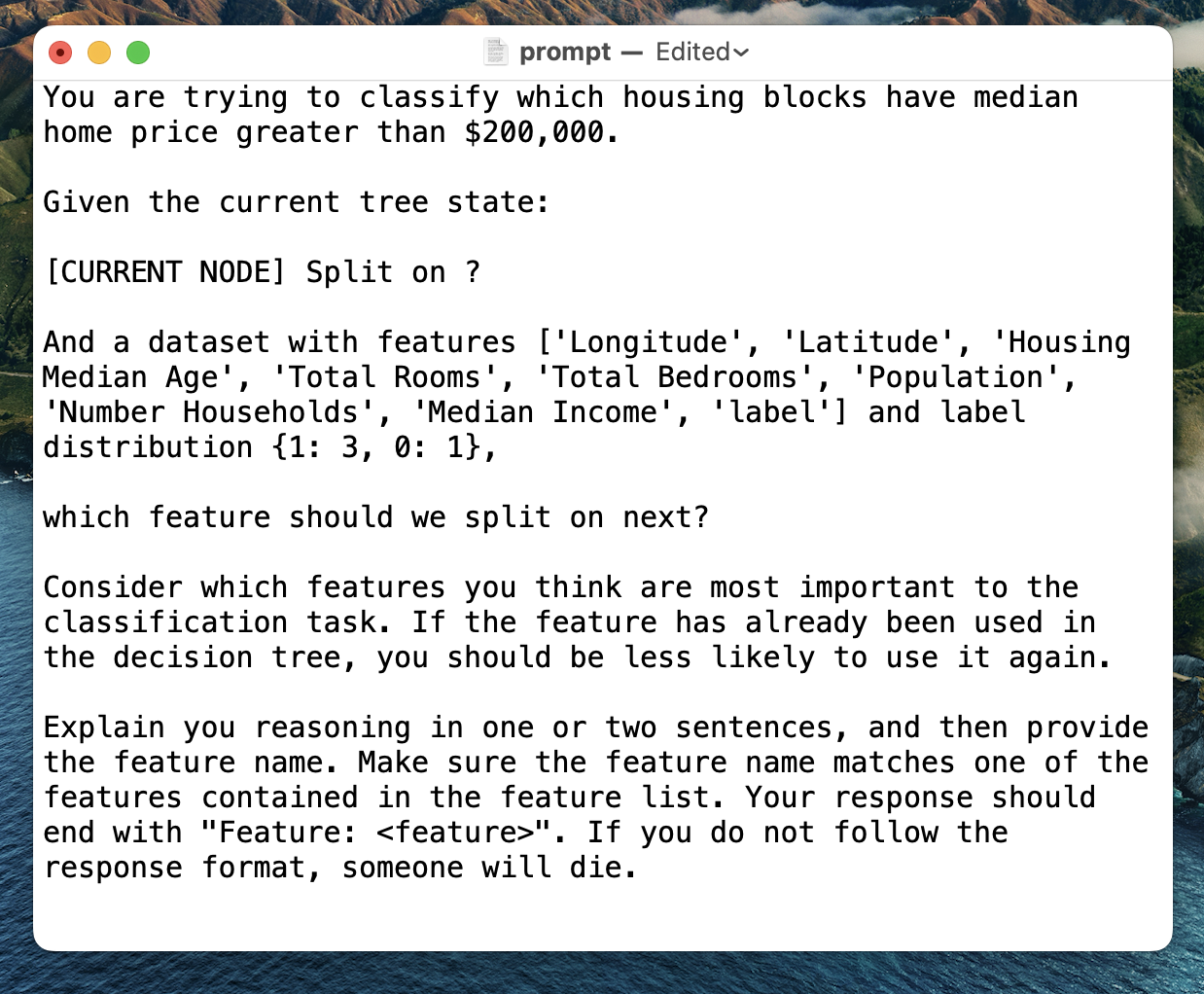
I try this approach on a few different Kaggle datasets: classifying whether median housing price exceeds $200,000, classifying mushroom edibiility, and classifying diabetes diagnosis. For each dataset, I hold out a test set of size 1,000, and use the remaining data to choose subsamples. I consider sample sizes 4, 8, 16, 32, 64, and 128. For each sample size, I generate 20 unique samples. For each of these samples, I train two decision trees: one using the language model feature selector, one using the standard algorithmic approach. Then I take the accuracy of the trees over the test set. Max depth is set to 3 for all decision trees.
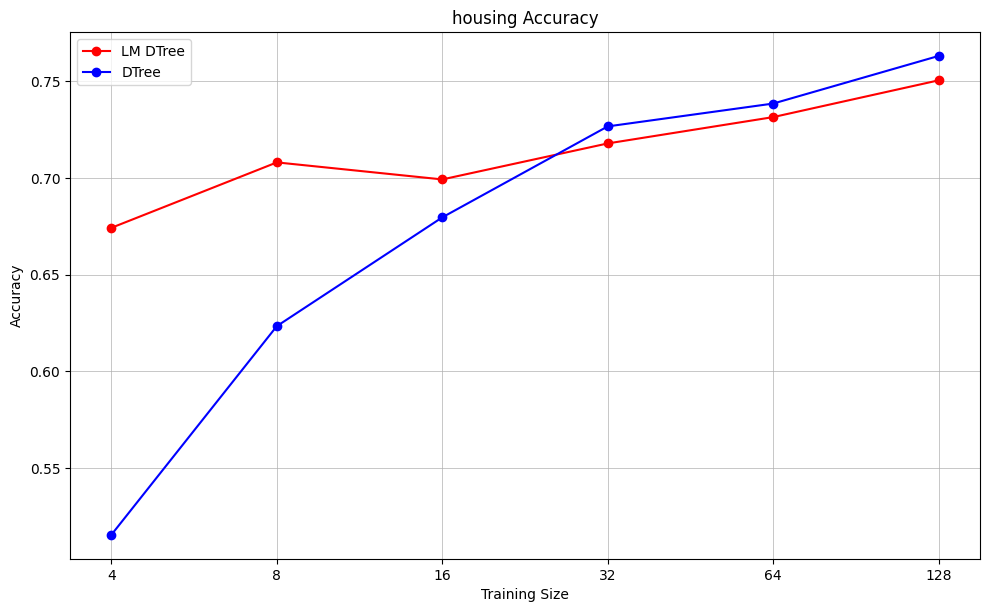
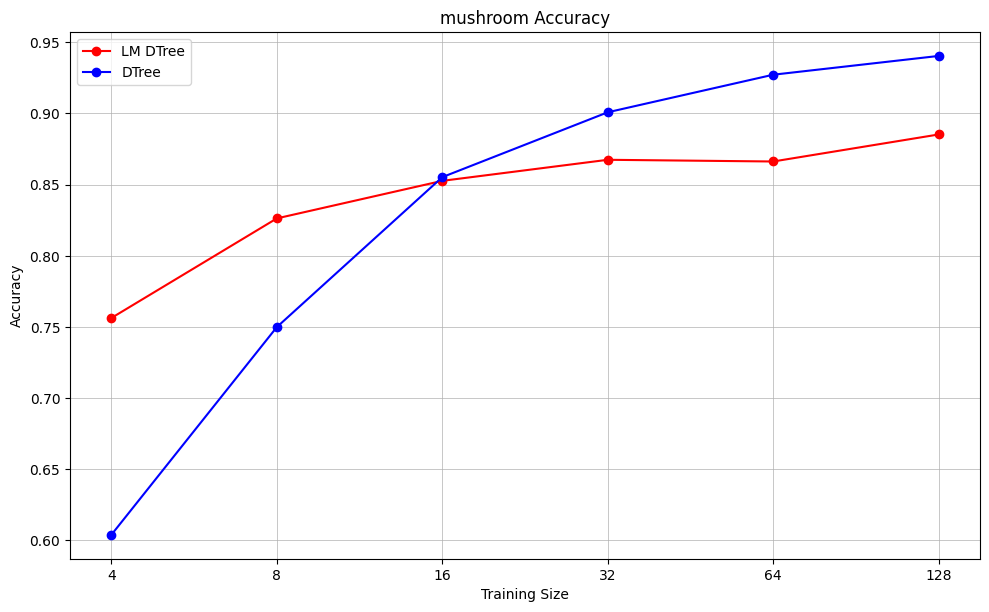
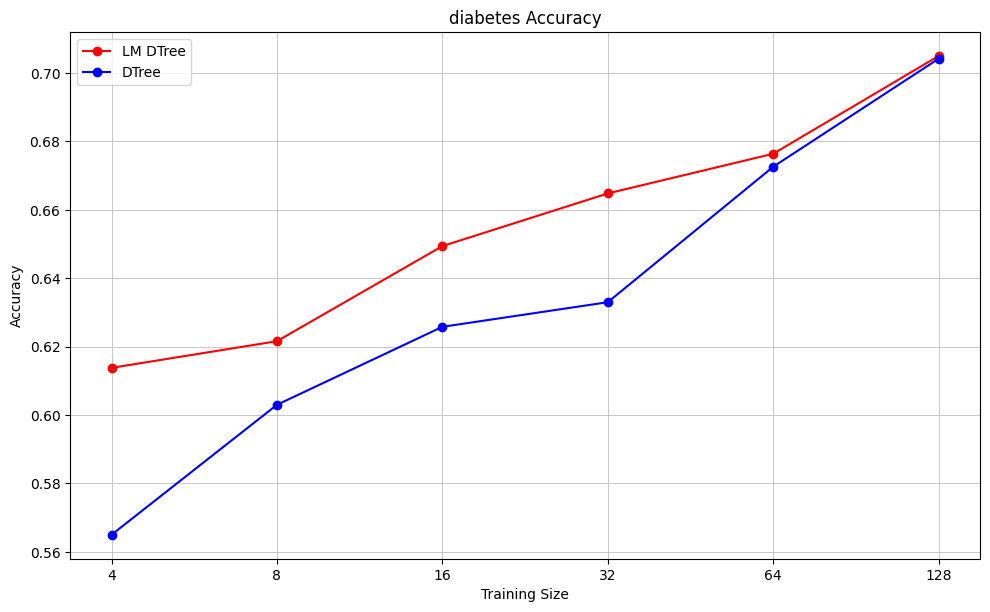
As expected, the language-model-augmented decision tree outperforms the standard decision tree for small sample sizes, but the gap closes as sample size increases.
The primary advantage of the language model is that it consistently chooses the most important feature for root node split (income in the housing example, odor in the mushroom example), while the algorithm often chooses other features for the root node split for small sample sizes.
Some other questions/ideas
-
At what point does the algo tree surpass the LM tree in performance? Can we quantify it/describe it as a function of the number of training points and size of the feature space?
-
Can we use language model suggestions as Bayesian priors and update with each training point? So the model dynamically handles the tradeoff between few-shot learner and scalable symbolic model?
-
Can we leverage this framework for bagging or boosting?
-
Need to think more about the language model -> symbolic model idea: Is it useful? What other work has been done in this direction? Better language for this framework?
-
Is there a future where generative langauge models are responsible for the majority of inference on quantitative data? Why/why not? At the moment I think P(this happens) > .5 because getting data for ML is hard, language models are convenient and comfortable interfaces, and costs tend toward negligible.